

You probably are already familiar with input/output and pipe redirection in Linux.
Let me tell you about a similar but advanced feature called process substitution.
You'll find two kinds of syntax for process substitution:
<(commands)or
>(commands)Let me go a bit in detail.
Bash Process Substitution
You'll find the process substitution can be used similar to STDOUT or STDIN redirection.
With <(commands) operator, you read from the substitution. This means that commands is set up to use it as stdout.
For example, the following command uses the output of ls *sh:
wc -l <(ls *sh)This is equivalent to:
ls *sh | wc -l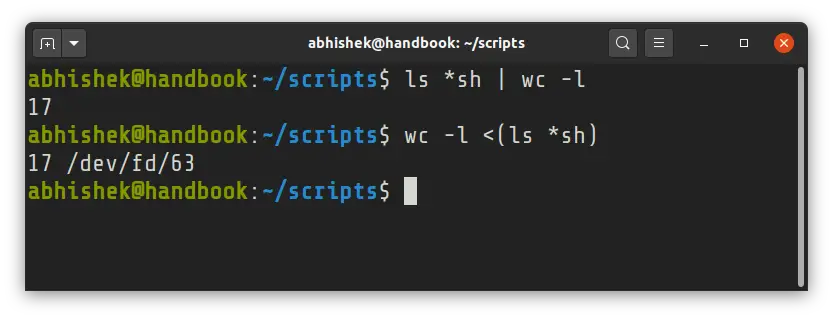
With >(commands) operator, you write to the substitution. This means that commands is set up to use it as stdin.
In other words, when you have a command that outputs to a file but you want it to write to some other command instead of the file.
Here's an example that should make things a bit more clear:
tar -cf >(ssh remote_server tar xf -) .You figure what it does? That's right. You just transferred all the contents of the current directory to a remote server. The archive file is created on the fly and is extracted on the server.
To be honest, >(...) operator is less common. You'll find that <(...) can be used more often.
So, what's the advantage of process substitution if it works like the regular input output redirection?
You'll realize the power and usefulness of bash process substitution when you have multiple command pipelines to combine in a single command.
Advantage of bash process substitution
Most obvious and most frequent use of process substitution is the comparison of the outputs of two programs. Let me show it to you with a practical example.
Let's say you have some C program files and their corresponding object files (.out file) with the same name in a directory.
ls *
aa.c aa.out bb.c bb.out cc.c cc.out ...Here's your objective. You want to check whether each C file has its corresponding output file with same name as the C file or not.
Your typical approach would be to list the files filtered on extension and then use the cut command with delimiter .(dot) to extract the file name without extension:
ls *.c | cut -d. -f1
aa
bb
cc
dd
Your typical approach would be to save the output of *.c and *.out files into temporary files and then compare these files with diff command. Am I right?
ls *.c | cut -d. -f1 > c.txt
ls *.out | cut -d. -f1 > out.txt
diff c.txt out.txt
rm c.txt out.txtYou could use the /tmp directory to create temporary files but you still have three lines of commands.
You can beautifully use the process substitution to replace all the above with a single command without creating temporary files:
diff <(ls *.c | cut -d. -f1) <(ls *.out | cut -d. -f1)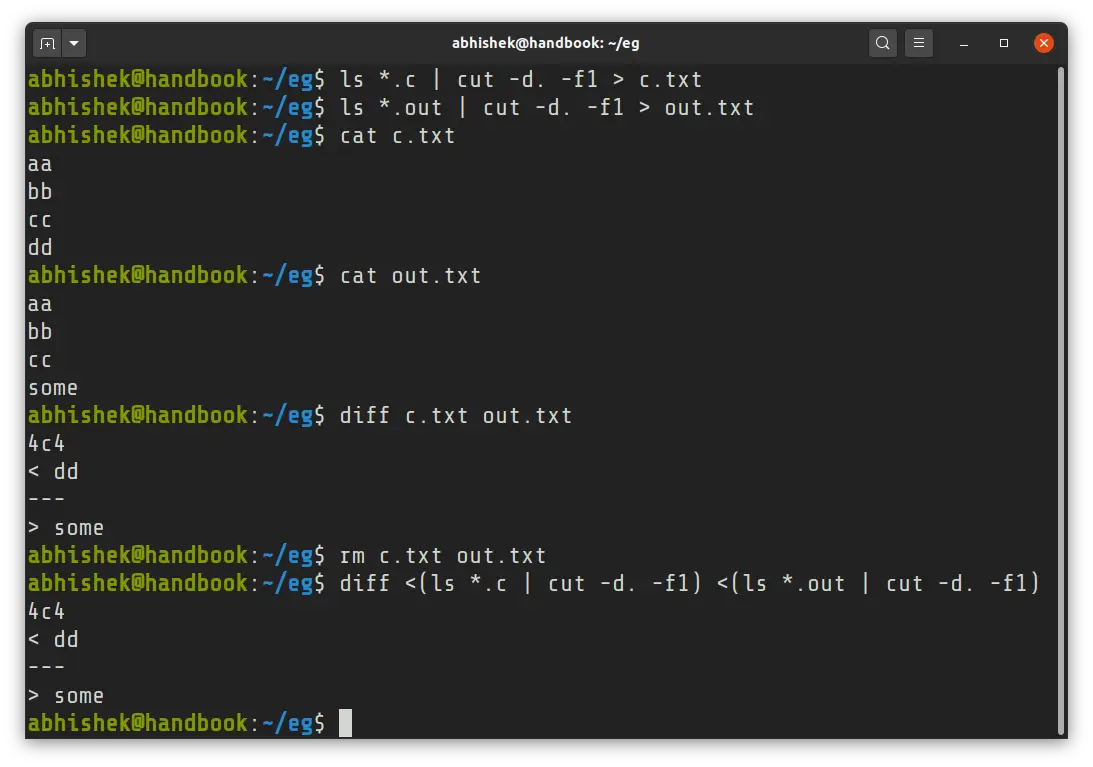
You didn't need to create any temp files here and that's the key about it. Here is my tip about when you should use process substitution.
Whenever you think you need a temporary file to do something, consider if process substitution can be used.
The process substitution is a bash feature and may or may not work with other shell.
I hope you would try and use process substitution in the future. As you can see, it's quite useful. I welcome your questions and suggestions.
