PenTesting 101: Using TheHarvester for OSINT and Reconnaissance
Gather intelligence about your target website with TheHarvester in this pen-testing practice tutorial.


Ever wonder how security pros find those hidden entry points before the real testing even begins? It all starts with what we call reconnaissance—the art of gathering intelligence. Think of it like casing a building before a security audit; you need to know the doors, windows, and air vents first.
In this digital age, one of the go-to tools for this initial legwork is TheHarvester.
At its heart, TheHarvester is a Python script that doesn't try to do anything fancy. Its job is straightforward: to scour publicly available information and collect things like email addresses, subdomains, IPs, and URLs. It looks in all the usual places, from standard search engines to specialized databases like Shodan, which is essentially a search engine for internet-connected devices.
We did something like this by fingerprinting with WhatWeb in an earlier tutorial. But TheHarvester is a different tool with more diverse information.
Step 1: Installing TheHarvester
If you're not using Kali Linux, you can easily install TheHarvester from its GitHub repository.
Option A: Using apt (Kali Linux / Debian/Ubuntu)
sudo apt update && sudo apt install theharvester
Option B: Installing from source (Latest Version)
git clone https://github.com/laramies/theHarvester.git
cd theHarvester
python3 -m pip install -r requirements.txt
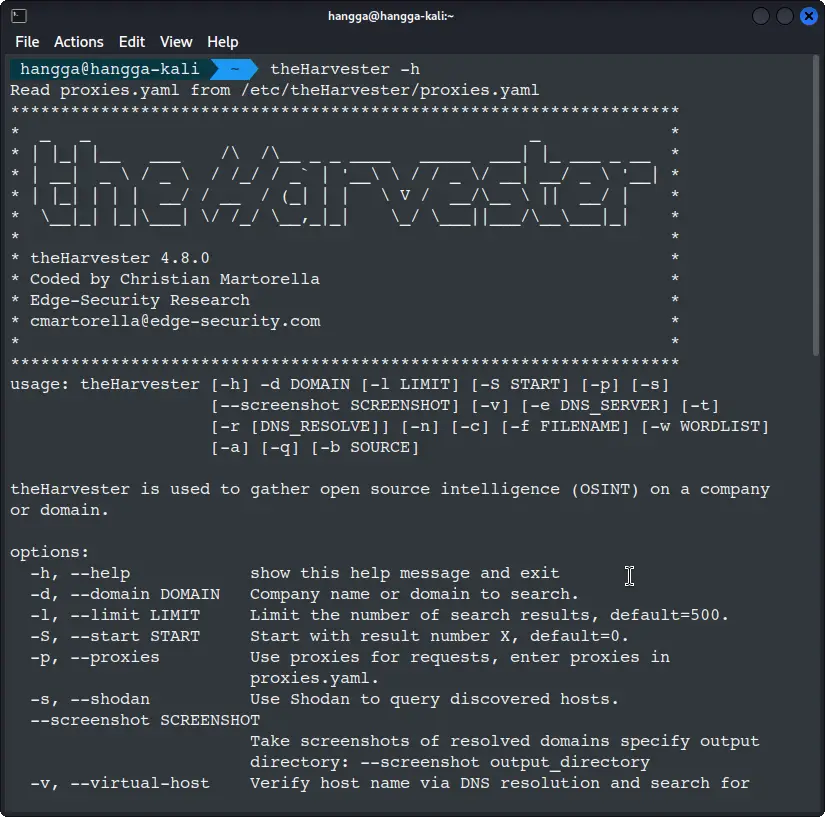
You can verify the installation by checking the help menu:
theHarvester -h
Step 2: Understanding the basic syntax
The basic command structure of TheHarvester is straightforward:
theHarvester -d <domain> -l <limit> -b <data_source>
Let's break down the key options:
-dor--domain: The target domain name (e.g.,vulnweb.com).-lor--limit: The number of results to fetch from each data source (e.g., 100, 500). More results take longer.-bor--source: The data source to use. You can specify a single source likegoogleor useallto run all available sources.-for--filename: Save the results to an HTML and/or XML file.
Step 3: Case Study: Reconnaissance on vulnweb.com
Let's use TheHarvester to discover information about our target, vulnweb.com. We'll start with a broad search using the google and duckduckgo sources.
Run a basic scan
theHarvester -d vulnweb.com -l 100 -b google,duckduckgo
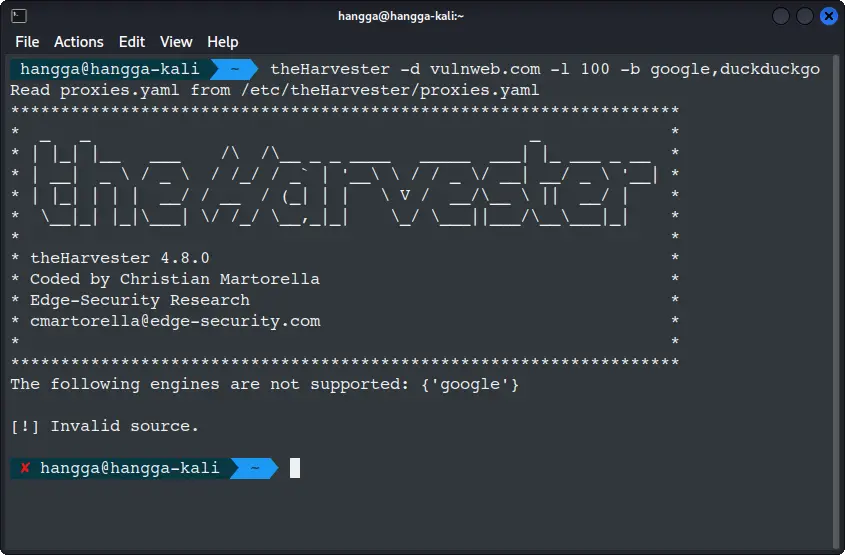
If you're seeing the error The following engines are not supported: {'google'}, don't worry—you're not alone. This is a frequent problem that stems from how TheHarvester interacts with public search engines, particularly Google.
Let's break down why this happens and walk through the most effective solutions.
Why Does This Happen?
The short answer: Google has made its search engine increasingly difficult to scrape programmatically.
Here are the core reasons:
- Advanced Bot Detection: Google uses sophisticated algorithms to detect and block automated requests that don't come from a real web browser. TheHarvester's requests are easily identified as bots.
- CAPTCHAs: When Google suspects automated activity, it presents a CAPTCHA challenge. TheHarvester cannot solve these, so the request fails, and the module is disabled for the rest of your session.
- Lack of an API Key (for some sources): Some data sources, like Shodan, require a free API key to be used effectively. Without one, the module will not work.
In the case of our example domain, vulnweb.com, this means we might miss some results that could be indexed on Google, but it's not the end of the world.
Solution: Use the "All" flag with realistic expectations
You can use -b all to run all modules. The unsupported ones will be gracefully skipped, and the supported ones will run.
theHarvester -d vulnweb.com -l 100 -b all
Now the output will look something like that.
Read proxies.yaml from /etc/theHarvester/proxies.yaml
*******************************************************************
* _ _ _ *
* | |_| |__ ___ /\ /\__ _ _ ____ _____ ___| |_ ___ _ __ *
* | __| _ \ / _ \ / /_/ / _` | '__\ \ / / _ \/ __| __/ _ \ '__| *
* | |_| | | | __/ / __ / (_| | | \ V / __/\__ \ || __/ | *
* \__|_| |_|\___| \/ /_/ \__,_|_| \_/ \___||___/\__\___|_| *
* *
* theHarvester 4.8.0 *
* Coded by Christian Martorella *
* Edge-Security Research *
* [email protected] *
* *
*******************************************************************
[*] Target: vulnweb.com
Read api-keys.yaml from /etc/theHarvester/api-keys.yaml
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
An exception has occurred: Server disconnected
[*] Searching Baidu.
Searching 0 results.
.....
.....
.....
The output is actually huge, spanning over 600 lines. You can view the complete output in this GitHub gist.
Analyzing the output
When TheHarvester finishes its work, the real detective work begins.
The Initial Chatter: Warnings and Status Messages
Right off the bat, you'll see a series of status checks and warnings:
Read api-keys.yaml from /etc/theHarvester/api-keys.yaml
An exception has occurred: Server disconnected
[*] Searching Baidu.
Searching 0 results.
[*] Searching Bing.
Searching results.
Don't let these alarm you. The "Server disconnected" and similar exceptions are TheHarvester's way of telling you that certain data sources were unavailable or timed out—this is completely normal during reconnaissance. The tool gracefully skips these and moves on to working sources.
The reconnaissance gold: Key findings
Here's where we strike valuable intelligence:
- Network infrastructure (ASN)
[*] ASNS found: 1
--------------------
AS16509
This reveals the Autonomous System Number, essentially telling us which major network provider hosts this infrastructure (in this case, AS16509 is Amazon.com, Inc.).
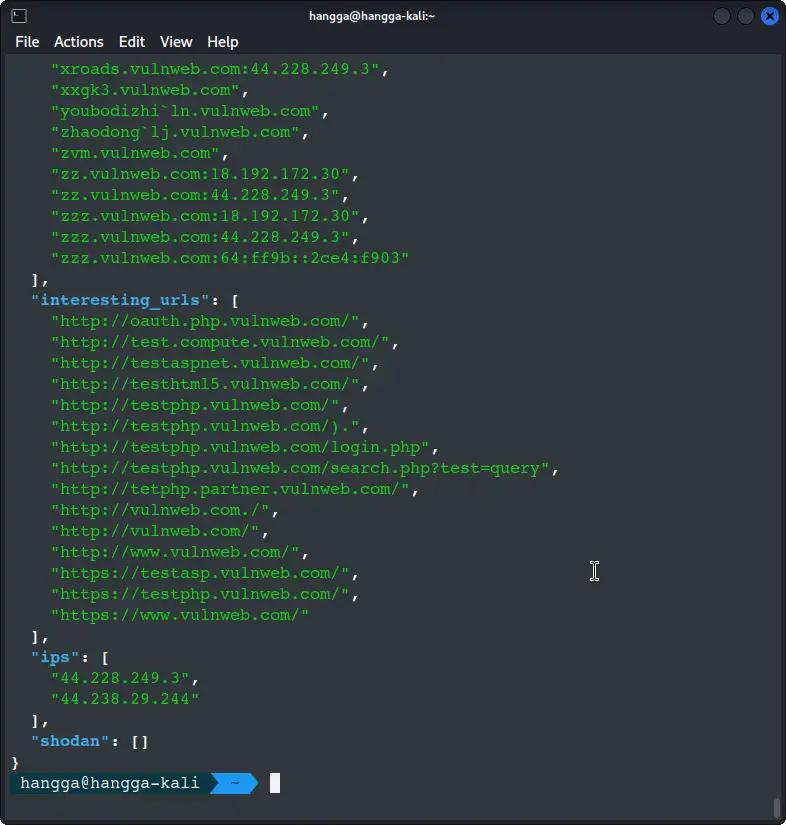
- The attack surface - interesting URLs
[*] Interesting Urls found: 15
--------------------
http://testphp.vulnweb.com/
https://testasp.vulnweb.com/
http://testphp.vulnweb.com/login.php
This is your target list! Each URL represents a potential entry point. Notice we've found:
- Multiple applications (
testphp,testasp,testhtml5) - Specific functional pages (
login.php,search.php) - Both HTTP and HTTPS services.
- IP address mapping
[*] IPs found: 2
-------------------
44.228.249.3
44.238.29.244
Only two IP addresses serving all this content? This suggests virtual hosting where multiple domains share the same server—valuable for understanding the infrastructure setup.
- The subdomain treasure trove
[*] Hosts found: 610
---------------------
testphp.vulnweb.com:44.228.249.3
testasp.vulnweb.com:44.238.29.244
This massive list of 610 hosts reveals the true scale of the environment. You can see patterns emerging:
- Application subdomains (
testphp,testasp) - Infrastructure components (
compute.vulnweb.com,elb.vulnweb.com) - Geographic distribution across AWS regions
- What's not there matters too
[*] No emails found.
[*] No people found.
For a test site like vulnweb.com, this makes sense. But in a real engagement, missing email addresses might mean you need different reconnaissance approaches.
From reconnaissance to action
So what's next with this intelligence? Your penetration testing roadmap becomes clear:
- Prioritize targets - Start with the login pages and search functions
- Scan the applications - Use tools like
niktoornucleion the discovered URLs - Probe the infrastructure - Run
nmapscans on the identified IP addresses - Document everything - Each subdomain is a potential attack vectort
In just minutes, TheHarvester has transformed an unknown domain into a mapped-out territory ready for deeper security testing.
Step 4: Expanding the search with more data sources
The real power of TheHarvester comes from using multiple data sources. Let's run a more comprehensive scan using bing, linkedin, and threatcrowd.
theHarvester -d vulnweb.com -l 100 -b bing,linkedin,threatcrowd
- Bing: Often returns different and sometimes more results than Google.
- LinkedIn: Can be useful for finding employee names and profiles associated with a company, which can help in social engineering attacks. For
vulnweb.com, this won't yield results, but for a real corporate target, it's invaluable. - Threat Crowd: An open-source threat intelligence engine that can often provide a rich list of subdomains.
Step 5: Using all sources and saving results
For the most thorough reconnaissance, you can use nearly all sources with the -b all flag.
It's also crucial to save your results for later analysis. Use the -f flag for this.
theHarvester -d vulnweb.com -l 100 -b all -f recon-results
This command will:
- Query all available data sources.
- Limit results to 100 per source.
- Save the final output to
recon-results.jsonandrecon-results.xml.
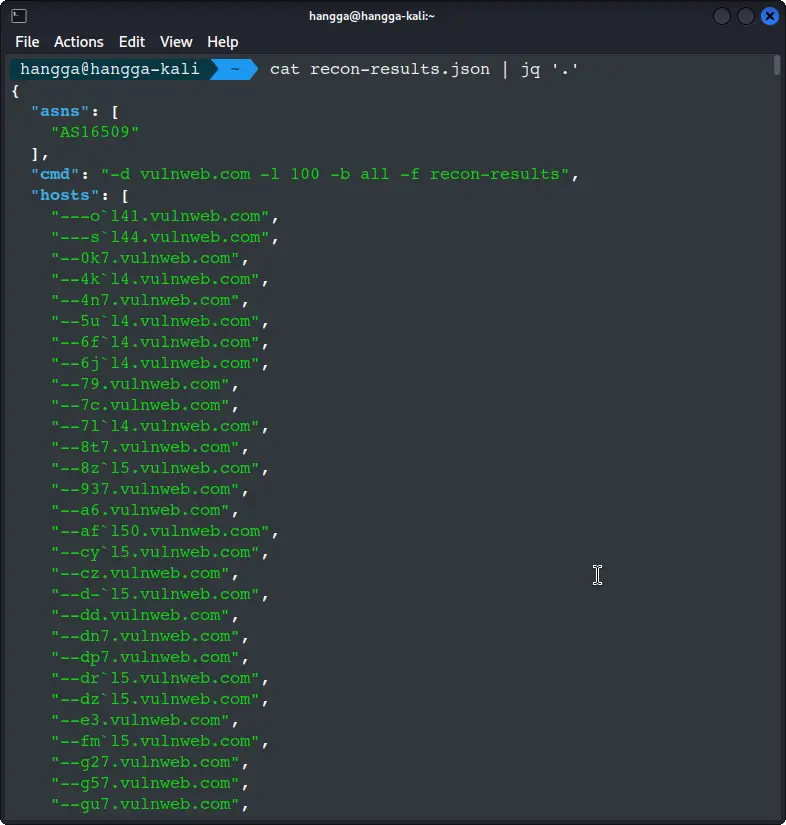
Read json files with cat and jq:
cat recon-results.json | jq '.'
Important notes and best practices
- Rate Limiting: Be respectful of the data sources. Using high limits or running scans too frequently can get your IP address temporarily blocked.
- Legality: Only use TheHarvester on domains you own or have explicit permission to test. Unauthorized reconnaissance can be illegal.
- Context is Key: TheHarvester is a starting point. The data it collects must be verified and analyzed in the context of a broader security assessment.
TheHarvester is a cornerstone tool for any penetration tester or security researcher. By following this guide, you can effectively use it to map out the digital footprint of your target and lay the groundwork for a successful security assessment.
About the author
Software engineer since 2008, passionate about tech and security. Seasonal security researcher and pentester who enjoys sharing knowledge.