

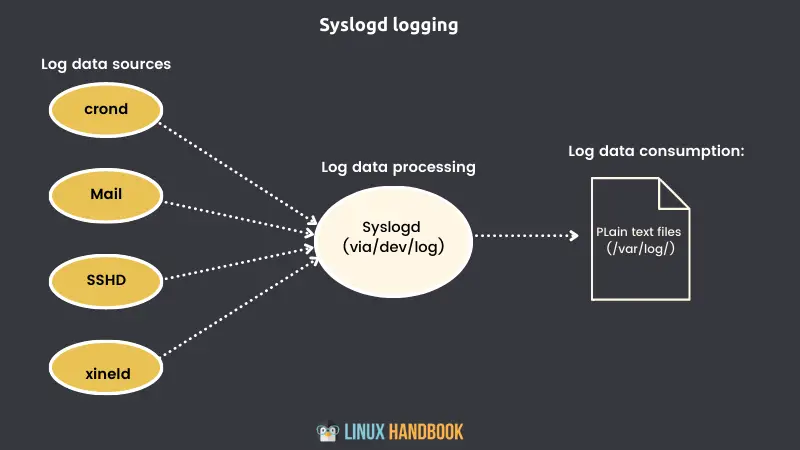
For decades, Linux logging has been managed by the syslogd daemon.
Syslogd would collect the log messages that system processes and applications sent to the /dev/log pseudo device. Then it would direct the messages to appropriate plain text log files in the /var/log/ directory.
Syslogd would know where to send the messages because each one includes headers containing metadata fields (including a time-stamp, and the message origin and priority).
In the wake of systemd’s relentless, world-conquering juggernaut, Linux logging is now also handled by journald. I say also because syslogd hasn’t gone anywhere, and you can still find most of its traditional log files in /var/log/. But you need to be aware that there’s a new sheriff in town whose (command line) name is journalctl.
 Abhishek Prakash
Abhishek Prakash
But this article is not about journald. The focus here is on syslog so let's dig it a bit more.
Logging with syslogd
All the logs generated by events on a syslogd system are added to the /var/log/syslog file. But, depending on their identifying characteristics, they might also be sent to one or more other files in the same directory.
With syslogd, the way messages are distributed is determined by the contents of the 50-default.conf file that lives in the /etc/rsyslog.d/ directory.
This example from 50-default.conf shows how log messages marked as cron-related will be written to the cron.log file. In this case, the asterisk (*) tells syslogd to send entries with any priority level (as opposed to a single level like emerg or err):
cron.* /var/log/cron.logWorking with syslogd log files doesn’t require any special tools like journalctl. But if you want to get good at this, you’ll need to know what kind of information is kept in each of the standard log files.
The table below lists the most common syslogd log files and
their purposes.
| Filename | Purpose |
|---|---|
| auth.log | System authentication and security events |
| boot.log | A record of boot-related events |
| dmesg | Kernel-ring buffer events related to device drivers |
| dpkg.log | Software package-management events |
| kern.log | Linux kernel events |
| syslog | A collection of all logs |
| wtmp | Tracks user sessions (accessed through the who and last commands) |
In addition, individual applications will sometimes write to their own log files. You’ll often also see entire directories like /var/log/apache2/ or /var/log/mysql/ created to receive application data.
Log redirection can also be controlled through any one of eight priority levels, in addition to the * symbol (for all priority levels) you saw before.
| Level | Description |
|---|---|
| debug | Helpful for debugging |
| info | Informational |
| notice | Normal conditions |
| warn | Conditions requiring warnings |
| err | Error conditions |
| crit | Critical conditions |
| alert | Immediate action required |
| emerg | System unusable |
Managing log files with syslogd
By default, syslogd handles log rotation, compression, and deletion behind the scenes without any help from you. But you should know how it’s done in case you ever have logs needing special treatment.
What kind of special treatment could a simple log ever require? Well, suppose your company has to be compliant with the transaction reporting rules associated with regulatory or industry standards like Sarbanes-Oxley or PCI-DSS. If your IT infrastructure records must remain accessible for longer periods of time, then you’ll definitely want
to know how to find your way through the key files.
To see the logrotate system in action, list some of the contents of the /var/log/ directory. The auth.log file, for instance, appears in three different formats:
- auth.log - The version that’s currently active, with new auth messages being written to it.
- auth.log.1 - The most recent file to have been rotated out of service. It’s maintained in uncompressed format to make it easier to quickly call it back into action should it be necessary.
- auth.log.2.gz - An older collection (as you can see from the .gz file extension in the following listing) that has been compressed to save space.
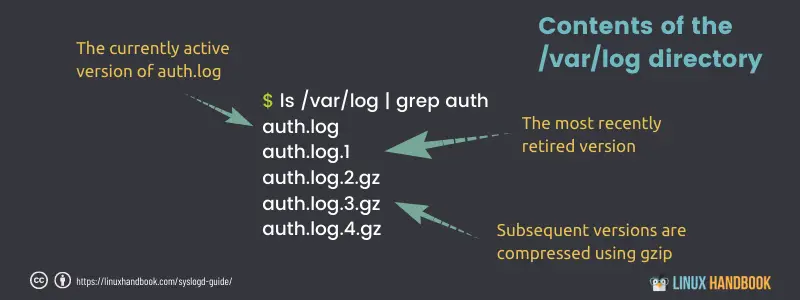
After seven days, when the next rotation date arrives, auth.log.2.gz will be renamed auth.log.3.gz, auth.log.1 will be compressed and renamed auth.log.2.gz, auth.log will become auth.log.1, and a new file will be created and given the name auth.log.
The default log rotation cycle is controlled in the /etc/logrotate.conf file. The values illustrated in this listing rotate files after a single active week and delete old files after four weeks.
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
# create new (empty) log files after rotating old ones
create
# packages drop log rotation information into this directory
include /etc/logrotate.The /etc/logrotate.d/ directory also contains customized configuration files for managing the log rotation of individual services or applications. Listing the contents of that directory, you see these config files:
$ ls /etc/logrotate.d/
apache2 apt dpkg mysql-server
rsyslog
samba
unattended-upgradeYou can view their content to see what kind of configuration they have on log rotation.
How to read the syslog files
You know you’ve got better things to do with your time than read through millions of lines of log entries.
Using cat should be avoided entirely here. It will simply dump thousands of lines on your screen.
I suggest using grep for filtering text through the files.
Using tail -f command allows you to read the current log file in real time. You may combine it with grep to filter on desired text.
In some cases, you may require to access the old, compressed logs. You may always extract the file first and then use grep, less and other commands to read its content, however, there is a better option. There are z commands like zcat, zless etc that let you work on the compressed files without explicitly extracting them.
A practical example of log analysis
Here’s an obvious example that will search through the auth.log file for evidence of failed login attempts. Searching for the word failure will
return any line containing the phrase authentication failure.
Checking this once in a while can help you spot attempts to compromise an account by guessing at the correct password. Anyone can mess up a password once or twice, but too many failed attempts should make you suspicious:
$ cat /var/log/auth.log | grep 'Authentication failure'
Sep 6 09:22:21 workstation su[21153]: pam_authenticate: Authentication failureIf you’re the kind of admin who never makes mistakes, then this search might come up empty. You can guarantee yourself at least one result by manually generating a log entry using a program called logger. Try it out doing something like this:
logger "Authentication failure"You could also pre-seed a genuine error by logging in to a user account and entering the wrong password.
As you can tell, grep did the job for you, but all you can see from the results is that there was an authentication failure. Wouldn’t it be useful to know whose account was involved? You can expand the results grep returns by telling it to include the lines immediately before and after the match.
This example prints the match along with the lines around it. It tells you that someone using the account david tried unsuccessfully to use su (switch user) to log in to the studio account:
$ cat /var/log/auth.log | grep -C1 failure
Sep 6 09:22:19 workstation su[21153]: pam_unix(su:auth): authentication
failure; logname= uid=1000 euid=0 tty=/dev/pts/4 ruser=david rhost=
user=studio
Sep 6 09:22:21 workstation su[21153]: pam_authenticate:
Authentication failure
Sep 6 09:22:21 workstation su[21153]: FAILED su for studio by davidWhat next?
Knowing the basics is one thing and applying the knowledge is a different thing. However, the knowledge of the fundamentals helps in various situations.
Now that you know the essentials of syslogs in Linux, you may have a slight better time while dealing with logs.
This article is an excerpt from the book Linux in Action by David Clinton. It is published by Manning Publication and you can get 30% discount on any Manning books using the code nlitsfoss22 at checkout time.
Enjoy learning Linux.
