

While the curl command was created to make things work without any human interaction, you can still use it to save output to a file.
And the easiest way to save a curl output to a file is to redirect the data stream to the file using > as shown:
curl http://lhb.com > file.txtBut there are multiple ways to save the output and how you want the file to be treated. Want to know how? Here you have it.
Save a cURL output to a file in Linux
Before I walk you through the how-to guide, it is important to know that, unlike wget, curl does not come pre-installed in most of the distros.
So if you're using Ubuntu/Debian base, then use the following command:
sudo apt install curlFor Fedora/RHEL base:
sudo dnf install curlFor Arch Linux:
sudo pacman -S curlOnce done, you can use the curl command with the -o flag to save the output to the file as shown:
curl http://example.com -o file.txt
For example, here, I downloaded an image from Pixabay having filename of Image.jpg:
curl https://cdn.pixabay.com/photo/2023/05/15/08/52/flower-7994489_960_720.jpg -o Image.jpg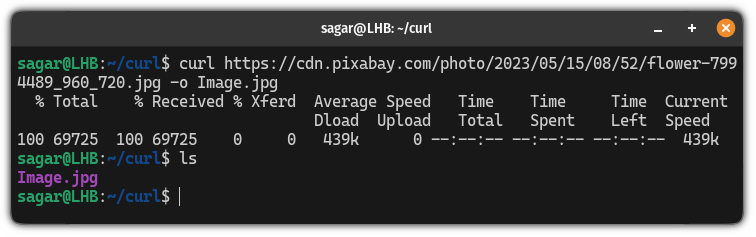
Save the file with the original filename
In the previous example, you had to give the filename by yourself that may or may not correspond to the original filename.
And there are times when you have to have the original filename.
In that case, you can skip adding a filename and use the -O as shown:
curl http://example.com -OFor example, here, I saved an image file without appending its filename:
curl https://cdn.pixabay.com/photo/2023/05/15/08/52/flower-7994489_960_720.jpg -O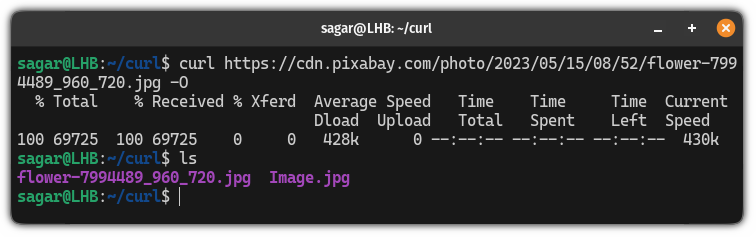
Save multiple files using the cURL command
If you want to save multiple files at once, then, you can use the cURL in the following manner:
curl http://Link-1.com http://Link-2.com http://Link-3.com -o File1 -o File2 -o File3In simple terms, you place your links first, then use the -o flag and add the name of each file accordingly.
For example, here, I saved 3 images:
curl https://pixabay.com/photos/bee-insect-honey-flower-7963186/ https://pixabay.com/photos/baseball-little-league-youth-kids-7985433/ https://pixabay.com/photos/iceberg-ice-ocean-cold-antarctica-8159694/ -o Image1.jpg -o Image2.jpg -o Image3.jpg 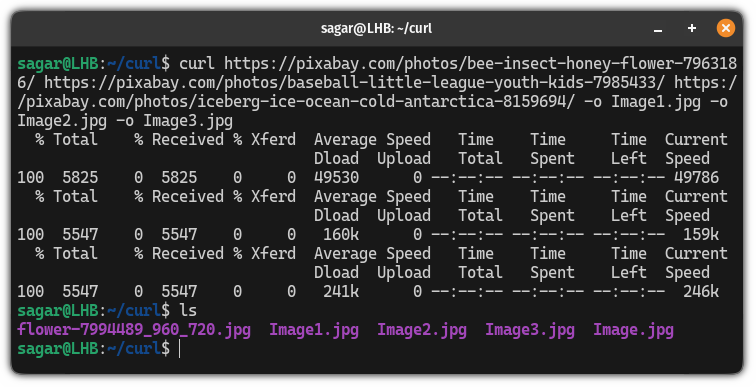
Save the file to a specific directory using cURL
By default, the curl command will save the file in the current working directory but that's not what we always want.
And with a little tweak to the previous command, you can save it to the desired directory. For that, you have to do is add a relative or absolute path before naming the file:
curl http://Link.com /path/to/filename.txtFor example, here, I saved an image file in a different directory (inside the home directory):
curl https://cdn.pixabay.com/photo/2023/05/15/08/52/flower-7994489_960_720.jpg -o ~/NewTest/Image.jpg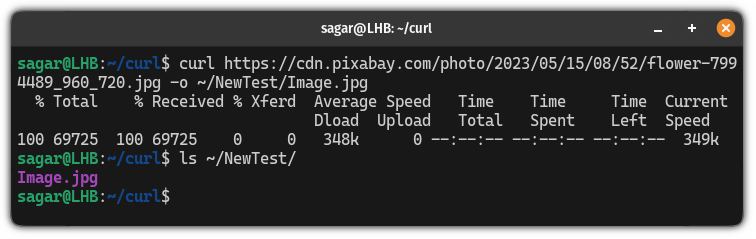
Here's how to use cURL to its max potential
The curl command has tonnes of features making it a go-to choice for many advanced users. And if you learn how to, you'll fall into the same category.
For that purpose, we made a detailed guide on how to use the curl command in Linux:

I hope you will find this guide helpful.
