

What is node affinity?
In the simplest of terms, Node Affinity gives you control over where your pods are scheduled. It matches pods to specific nodes or groups of nodes based on specific criteria. This is a really cool feature.
Advantages of node affinity
There are two main uses I can see:
- Resource Management: For example, Pod schedule on GPU nodes for AI workloads or SSD nodes for DB).
- Performance Optimization: Placing pods together that communicate frequently, to optimize latency.
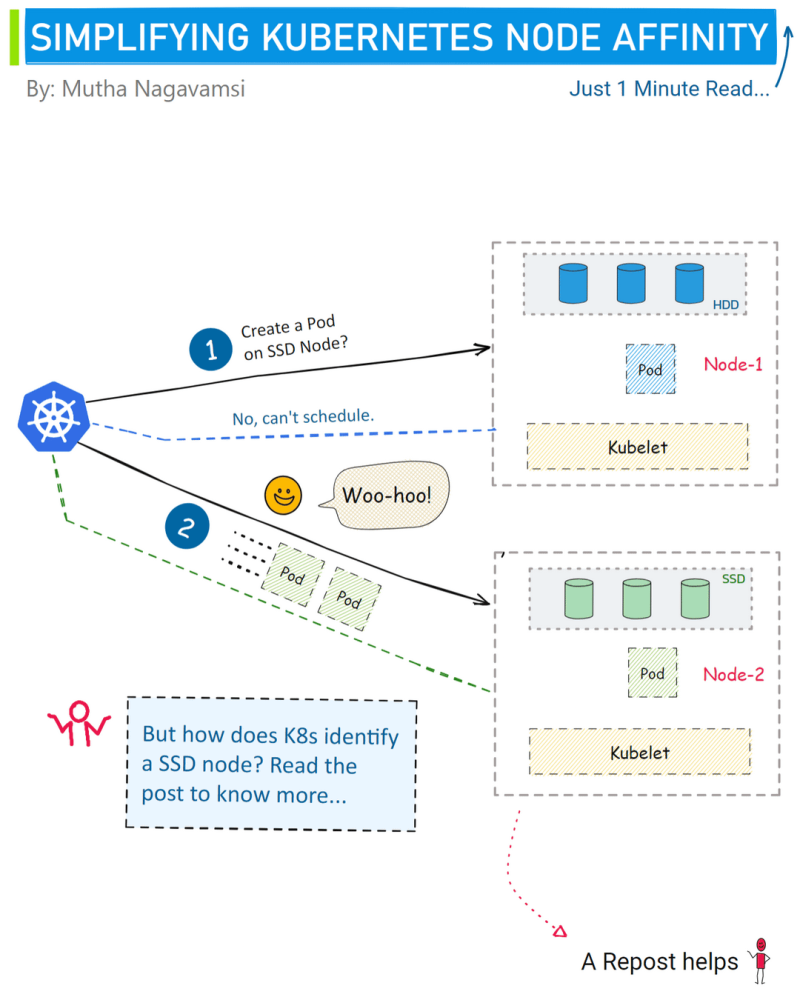
How exactly node affinity works?
Using node labels.
Nodes, like pods, can be assigned labels which are key-value pairs that act as metadata. Node Affinity uses these labels to determine where to schedule pods.
For example, the deployment below creates 2 nginx pods. Pods have label "app=nginx".
Here is the Kubernetes deployment job.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "disk"
operator: In
values:
- "ssd"How does K8s identify SSD nodes?
In the affinity section of config above, matchExpressions defines that if the node label "disk" matches to "ssd" the pod will be scheduled on that node.
In short:
- The config matches nodes with label "disk=ssd".
- This ensures pods run on SSD storage.
- So we get better performance for nginx.
I hope it's clear. That's it from me today. If you need any clarification, do let me know. Before you leave, don't forget to smile😁
