

curl and Wget are the two most common utilities for making requests to servers from the Linux command line.
If you ever find yourself swapping between the two, one is just piquing your curiosity, or you have ever just seen some good old discussion online about it, there are some differences that might be helpful to know about.
While you'll hopefully have a smooth experience using either, knowing the basic differences between the two will help you have a better grasp on using both (and hopefully resolve anything from the aforementioned question-filled discussions).
Main difference between curl and Wget: How output is saved
The single most visible difference curl and Wget is that by default Wget saves the queried webpage to the system, whereas curl displays it in the terminal output but doesn't save it.
Let's start with a simple example of making a request to Arch Linux's homepage, https://archlinux.org.
We'll first make the request with curl.
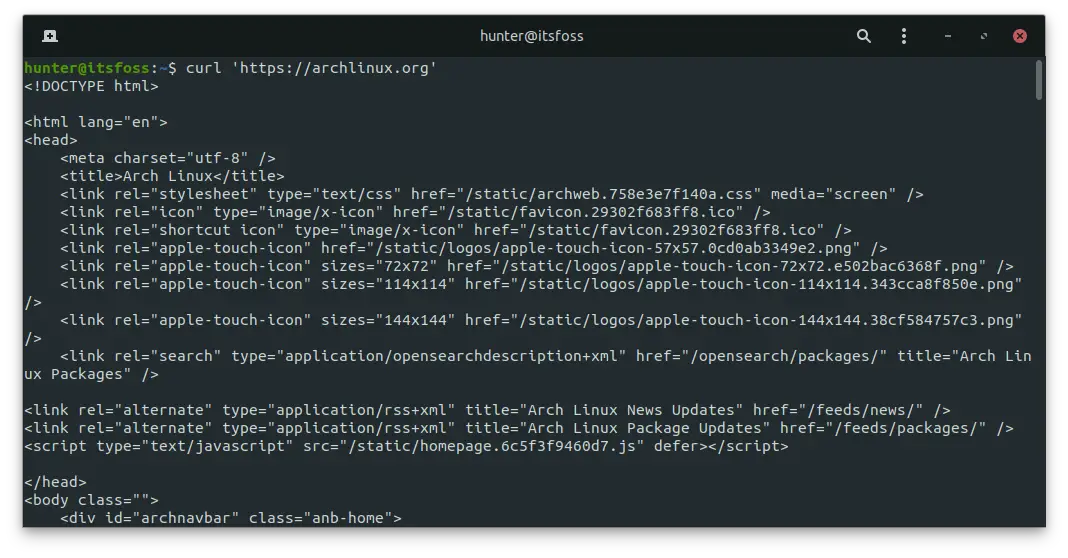
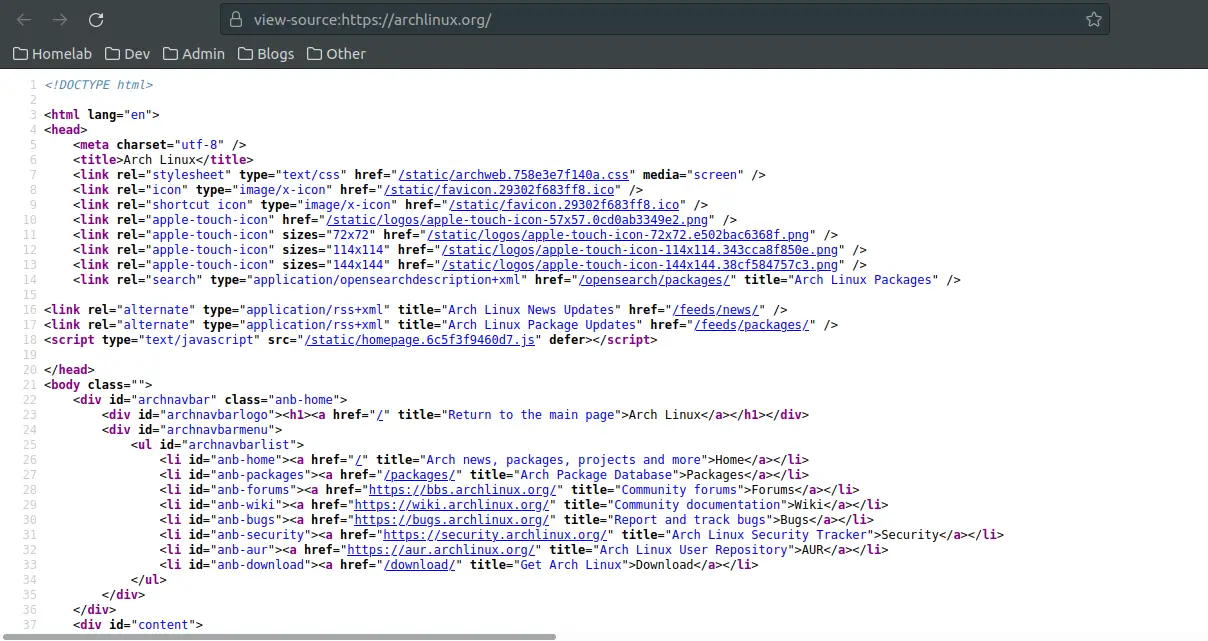
curl 'https://archlinux.org'Notice how curl command outputs the raw content of the webpage? It's as if you clicked the View Source button on a web browser.
Let's try fetching the same website with Wget:
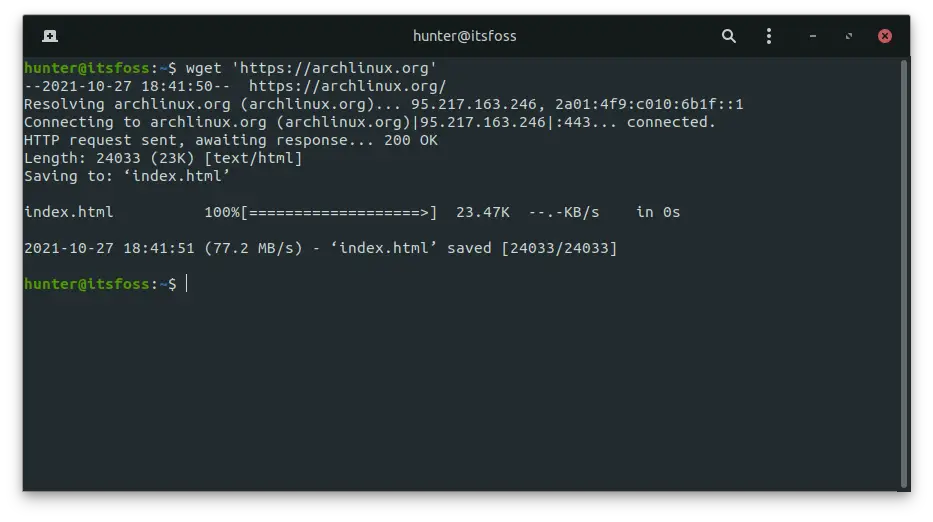
wget 'https://archlinux.org'Look at that, Wget didn't show the content of the webpage like curl did. But if Wget didn't show it, where did it put it?
That's where the first main difference between the two programs comes in.
By default, Wget is putting the website's content to a file named index.html:
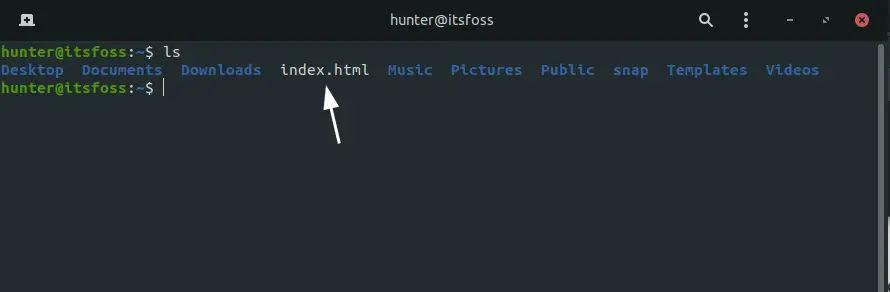
You could then see the actual contents of the file by running cat index.html, which would produce the same output you saw with the curl command:
If you want to save the file with curl, you have to use the -o option:
curl -o <output_file> <web_URL>Other notable differences
Besides that, that's actually pretty much the only difference you'll likely notice when using curl and Wget. There are a few others though that may be of interest, but they probably won't affect your usage of either tool too much, if at all, as an end user.
Support
curl is much more utilized than Wget, being used in environments like mobile phones, your computer (including OSs such as Windows and macOS), and even internet-of-things devices such as smartwatches, smart fridges, and other similar items.
Developer Usage
This next part is mostly of concern for developers. Curl has libraries to support network requests in programming languages such as C, while wget is strictly a command-line too and won't work very well if you need to interact with it from a programming language.
Part of that ties back to the previous reason, and contributes to why curl is widely used across different kinds of environments and devices.
Wrapping Up
And that's about it! Hopefully, you've now seen that the differences between the two are much smaller than some may make it out to be.
If you ever decide to choose one tool long-term though, I would definitely recommend curl, with it being what I use in my own projects, and it just being much more widely used than Wget.
Want a more full run-down between the two? Check out the curl vs Wget article by Daniel Stenberg (creator of curl), which goes into a bunch of more-advanced stuff that differs between the two tools.
