

I have a strange question for you.
Has your Linux system ever complained that you had no space left while you clearly still have more than enough?
It happened to me, that I had many GB left, but my Linux system complained that no space was left. This is when I learned about inodes.
inodes in brief
Inodes stores metadata for every file on your system in a table-like structure usually located near the beginning of a partition. They store all the information except the file name and the data.
Every file in a given directory is an entry with the filename and inode number. All other information about the file is retrieved from the inode table by referencing the inode number.
Inodes numbers are unique at the partition level. Every partition has its own inode table.
What is inode in Linux?
Inode stands for Index Node. Although history is not quite sure about that, it is the most logical and best guess they came up with. It used to be written I-node, but the hyphen got lost over time.
As describe on linfo.org:
An inode is a data structure … … that stores all the information about a file except its name and its actual data.
Inodes stores metadata about the file it refers to. This metadata contains all the information about the said file.
- Size
- Permission
- Owner/Group
- Location of the hard drive
- Date/time
- Other information

Every used inode refers to 1 file. Every file has 1 inode. Directories, character files, and block devices are all files. They each have 1 inode.
For each file in a directory, there is an entry containing the filename and the inode number associated with it.
Inodes are unique at the partition level. You can have two files with the same inode number given they are on different partitions. Inodes information is stored in a table-like structure in the strategic parts of each partition, often found near the beginning.
How to check inode in Linux?
You can easily list the inodes number with the following command:
ls -iThe following pictures show my root directory with corresponding inode numbers.
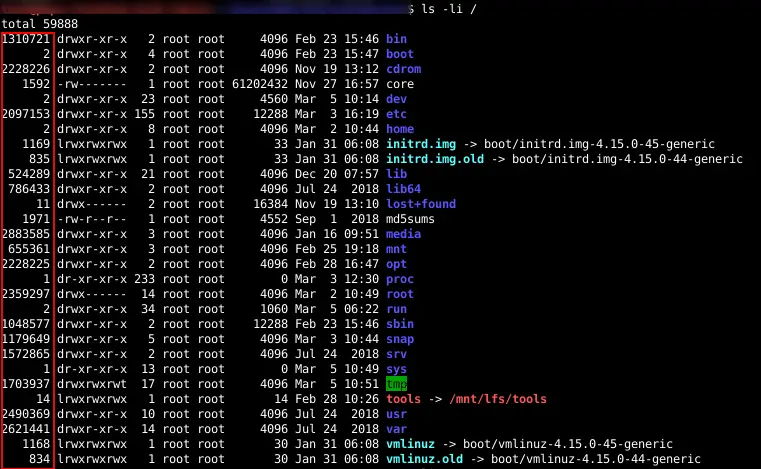
The amount of inodes each file system has is decided when you create the filesystem. For most users, the default number of inodes is more than sufficient.
The default setting when creating a filesystem will create 1 inode per 2K bytes of space. This gives plenty of inodes for most systems. You will more than likely run out of space before you run out of inodes. If need be, you can specify how many inodes to create when creating a file system.
If you run out of inodes, you will be unable to create new files. Your system will also be unable to do so. This is not a situation most users will encounter but it is possible.
For example, a mail server will store a huge amount of very small files. Lots of those files will be below 2K bytes. It is also expected to grow constantly. Therefore a mail server is at risk of running out of inodes way before running out of space.
Some file systems like Btrfs, JFS, XFS have implemented dynamic inodes. They can increase the number of inodes available if needed.
How to see inode usage?
When a new file is created, it is assigned an inode number and a file name. An inode number is a unique number within that file system. Both name and inode number are stored as entries in a directory.
When I ran the ls command “ls -li /” the file name and inodes number are what was stored in the directory /. The remaining information user, group, file permissions, size, etc was retrieved from the inode table using the inode number.
You can list inode information for each file system with the df command in Linux:
df -hi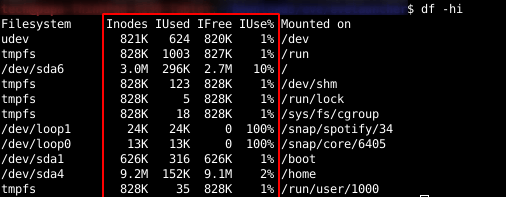
Inodes & Soft/Hard link
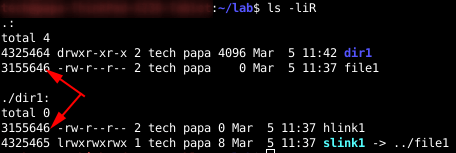
A soft link or symbolic link is a well-known feature of Linux. But what happens with Inodes when you create a symbolic link in Linux? In the next picture I have a directory called “dir1“, a file named “file1” and inside “dir1” I have a soft link called “slink1” which points to “../file1“
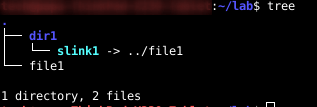
Now I can list recursively and show the inode information.
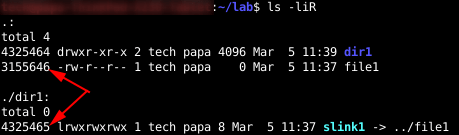
As expected, dir1 and file1 have different inode numbers. But so does the soft link. When you create a soft link, you create a new file. In its metadata, it points to the target. For every soft link you create, you use one inode.
After creating a hard link in dir1 with the ln command:
ln ../file1 hlink1Listing of inodes number gives me the following information:
You can see that “file1″ and “hlink1” have the same inode number. Truthfully, hard links are possible because of inodes. A hard link does not create a new file. It only provides a new name for the same data.
In older versions of Linux, it was possible to hard link a directory. It was even possible to have a given directory be its own parent. This was made possible because of inode implementation. This is now restricted to prevent users from creating a very confusing structure of directories.
Other implications of inodes
The way inodes work is also why it is impossible to create a hard link across the different file systems. Allowing such a task would open the possibility of having conflicting inode numbers. A soft link on the other hand can be created across the different file systems.
Because a hard link has the same inode number as the original file, you can delete the original file and the data is still available through the hard link. All you did, in this case, is remove one of the names pointing to this inode number. The data linked to this inode number will remain available until all names associated with it are deleted.
Inodes are also a big reason why a Linux system can update without the need to reboot. This is because one process can use a library file while another process replaces that file with a new version. Therefore, creating a new inode for the new file. The already running process will keep using the old file while every new call to it will result in using the new version.
Another interesting feature that comes with inodes is the ability to store the data in the inode itself. This is called Inlining. This storing method has the advantage of saving space because no data block will be needed. It also increases the lookup time by avoiding more disk access to get the data.
Some file system like ext4 has an option called inline_data. When enabled, it allows the operating system to store data this way. Due to size limitations, inlining only works for very small files. Ext2 and later will often store soft link information this way. That is if the size is no more than 60 Bytes.
Conclusion
Inodes are not something you interact directly with, but they play an important role. If a partition is to contain many very small files, like a mail server, knowing what they are and how they work can save you a lot of problems down the road.
I hope you liked this article and learned something new and important about inode in Linux. Subscribe to our website to learn more Linux-related information.
