

Curl is an excellent tool for downloading files in the Linux terminal.
The usual syntax to download a file with the same name as the original file is pretty simple:
curl -O URL_of_the_fileThis works most of the time. However, you'll notice that sometimes when you are downloading a file from GitHub or SourceForge, it doesn't fetch the correct file.
For example, I was trying to download archinstall script in tar gz format. The files are located on the release page.
If I open this source code link in a browser, it gets me the source code in .tar.gz format.
However, if I use the terminal to download the same file using curl command, I get a small file that is not in the correct archive format.
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
When I run the file command to know the exact file type, it tells me that it is an HTML document.
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators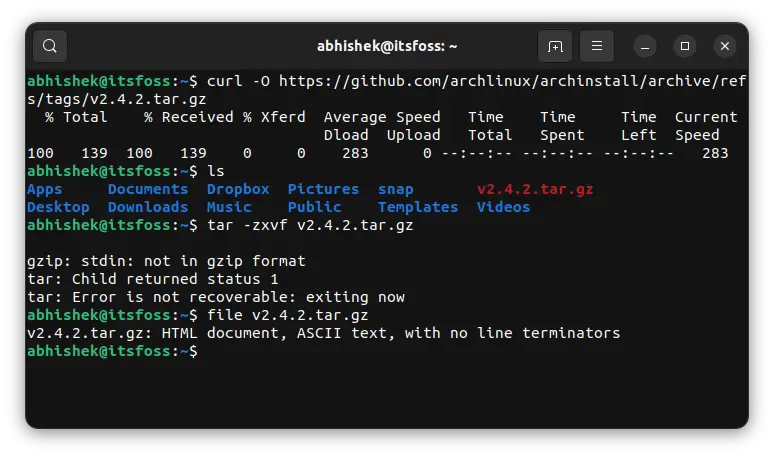
HTML document instead of the archive zip or tarball? Where's the problem? Let me show you the quick fix.
Properly downloading archive file with curl
The problem here is that the URL you have redirects to the actual archive file. To get that, you need to use additional options.
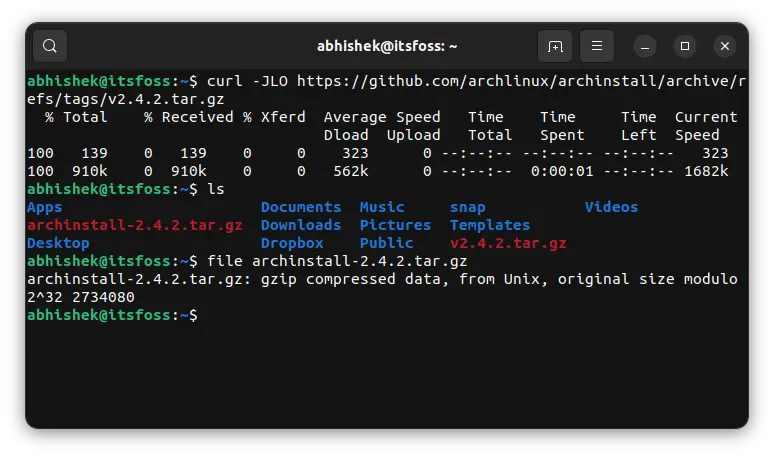
curl -JLO URL_of_the_fileThe options can be in any order. It's just easier to remember J LO (Jennifer Lopez).
Here's a quick explanation of the options based on the man page of the curl command.
- J: This option tells the -O, --remote-name option to use the server-specified Content-Disposition filename instead of extracting a filename from the URL.
- L: If the server reports that the requested page has moved to a different location (indicated with a Location: header and a 3XX response code), this option will make curl redo the request on the new place.
- O: With this option, you don't need to specify the output filename for the download.
As you can see in the screenshot below, I was able to download the correct file this time with the curl -JLO option.
Bonus tip: Do you need to log in?
This works for the public files. But if you try to download files from private repositories or GitLab, then you may see a message about redirection to the login page.
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
In such cases, please provide the API token with -H option.
Curl or wget, both commands can encounter this issue.
I hope this quick little tip helps you correctly download archive files with Curl. Let me know if you still facing problems with curl downloads.
