

Regex (Regular Expressions) is like a super-powered search function with pattern recognition. Think of it as upgrading from "find this exact word" to "find anything that matches this flexible pattern." It's your Swiss Army knife for text manipulation.
Core Concepts: Building Blocks
Let's talk about the basic elements of a regex, the characters that make regex work.
Literal Characters
The simplest regex - exactly what you type.
# Find "cat" in text
grep "cat" file.txt
Metacharacters: The Special Operators
These characters have superpowers - they don't match themselves but control pattern behavior.
# These are metacharacters: . ^ $ * + ? { } [ ] \ | ( )
Essential Regex Symbols Reference

| Symbol | Meaning | Example | Matches |
|---|---|---|---|
. |
Any single character | c.t |
cat, cut, c@t |
^ |
Start of line | ^Hello |
Lines starting with "Hello" |
$ |
End of line | bye$ |
Lines ending with "bye" |
* |
Zero or more of preceding | ca*t |
ct, cat, caat, caaat |
+ |
One or more of preceding | ca+t |
cat, caat, caaat |
? |
Zero or one of preceding | colou?r |
color, colour |
{n} |
Exactly n occurrences | a{3} |
aaa |
{n,} |
n or more occurrences | a{3,} |
aaa, aaaa, aaaaa |
{n,m} |
Between n and m occurrences | a{2,4} |
aa, aaa, aaaa |
[abc] |
Any character in brackets | [aeiou] |
Any vowel |
[^abc] |
Any character NOT in brackets | [^0-9] |
Any non-digit |
[a-z] |
Character range | [a-zA-Z] |
Any letter |
\ |
Escape special characters | \. |
Literal dot |
| |
OR operator | cat|dog |
cat or dog |
() |
Grouping | (cat)+ |
cat, catcat, catcatcat |
Character Classes: Pre-Built Shortcuts
| Shorthand | Equivalent | Meaning |
|---|---|---|
\d |
[0-9] |
Any digit |
\D |
[^0-9] |
Any non-digit |
\w |
[a-zA-Z0-9_] |
Word character |
\W |
[^a-zA-Z0-9_] |
Non-word character |
\s |
[ \t\n\r\f] |
Whitespace |
\S |
[^ \t\n\r\f] |
Non-whitespace |
Practical examples to practice regex knowledge
Here are some examples of regex in action. I am using grep command for pattern matching. You can also use sed or awk or even a programming language like Python.
1. Basic email validation
This is the content of emails.txt that contains some invalid email formats too.
[email protected]
invalid-email
[email protected]
test@test
[email protected]
not_an_email.com
[email protected]
The goal is to only match the valid email addresses. Focus on the regex pattern inside quotes.
grep -E "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$" emails.txt
Email construction is like building blocks: ^ starts from line beginning, [a-zA-Z0-9._%+-]+ matches username with one or more occurence of letters/numbers/and symbols, @ is literal @, [a-zA-Z0-9.-]+ matches domain name with any occurences of letters/numbers, \. matches literal dot, [a-zA-Z]{2,} matches extension (2+ letters), $ ensures line ends here.
This will be the output of the command:
[email protected]
[email protected]
[email protected]
[email protected]
2. Phone number extraction
This is the content of contacts.txt that contains some invalid phone number formats too. The correct format is to have 3 digits for area code, 3 for exchange and 4 for number. This is typical US style of phone number, and they often have phone numbers displayed with separators, too.
John Smith: (555) 123-4567
Call me at 555.987.6543
Phone: 555-555-5555
Invalid: 55-555-5555
Emergency: (911) 911-9111
Contact: 5551234567
Here's the regex that filters only the correct phone numbers. The -o ensures that regex only returns the matching part from the line.
grep -oE "\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4}" contacts.txt
Phone patterns as flexible templates: \(? = optional opening parenthesis, \d{3} = exactly 3 digits (area code), \)? = optional closing parenthesis, [-.\s]? = optional separator (dash/dot/space), \d{3} = 3 digits (exchange), another optional separator, \d{4} = 4 digits (number).
This will be the output of the command.
(555) 123-4567
555.987.6543
555-555-5555
(911) 911-9111
Did you notice the impact of -o option of grep? The putput doesn't contain the entire matching lines, only the part that matches the
3. Extract IP address
This is our log.txt file that contains some IP addresses.
2024-01-15 10:30:22 192.168.1.100 GET /index.html
2024-01-15 10:31:45 10.0.0.55 POST /api/login
Invalid IP: 999.999.999.999
2024-01-15 10:32:10 172.16.254.1 GET /dashboard
Not an IP: 192.168.1
2024-01-15 10:33:33 8.8.8.8 DNS lookup
This is the regex that will extract the matching pattern:
grep -oE "([0-9]{1,3}\.){3}[0-9]{1,3}" log.txt
IP addresses follow dot-separated quartets: ([0-9]{1,3}\.) captures 1-3 digits followed by literal dot, {3} repeats this pattern 3 times, [0-9]{1,3} matches final 1-3 digits. Like building "123.456.789.012" format.
192.168.1.100
10.0.0.55
999.999.999.999
172.16.254.1
8.8.8.8
Yes, I know that 999.999.999.999 is not a valid IP address but the idea here was to match numbers in the pattern and extract them.
4. Password strength checker
Here's a sample file with random passwords of varying length.
Password123
weakpass
STRONGPASSWORD
Strong123Pass
12345678
Abcd1234
short1A
VeryLongButNoNumbers
This is the regex that you can use with grep:
grep -E "^(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{8,}$" passwords.txt
Lookaheads act like security checkpoints: ^ starts line, (?=.*[a-z]) = "somewhere ahead find lowercase", (?=.*[A-Z]) = "somewhere ahead find uppercase", (?=.*\d) = "somewhere ahead find digit", .{8,} = match 8+ characters, $ ends line. All conditions must pass.
Run it and you should see an output like this:
Password123
Strong123Pass
Abcd1234
5. URL extraction
Here's a sample HTML code and we are going to extract the URLs from it.
<html>
<body>
Visit https://example.com for more info.
Check out http://blog.company.net/articles
Invalid: ftp://files.server.com
Also see https://secure.payment.org/checkout?id=123
Email: mailto:[email protected]
</body>
</html>
This is the regex you could use. Again, mind the use of -o to extract only the matching part of the lines.
grep -oE "https?://[a-zA-Z0-9./?=_%:-]*" webpage.html
URL patterns mimic web addresses: https? = "http" with optional "s" (s? means zero or one occurence of s), :// = literal protocol separator, [a-zA-Z0-9./?=_%:-]* = any web-safe characters (domains, paths, parameters). Like grabbing complete web links.
https://example.com
http://blog.company.net/articles
https://secure.payment.org/checkout?id=123
6. Extracting date formats
From the various kinds of date formats listed here:
Meeting on 12/25/2024
Invalid: 13/45/2024
Project due: 01/15/2025
Bad format: 1/1/24
Conference: 03/30/2024
ISO format: 2024-12-25
Another ISO: 2025-01-15
Wrong: 24-12-2024
Let's extract the ones in MM/DD/YYYY format:
grep -oE "(0[1-9]|1[0-2])/(0[1-9]|[12][0-9]|3[01])/[0-9]{4}" dates.txt
Date validation uses logical ranges: (0[1-9]|1[0-2]) = months 01-09 OR 10-12, / = literal slash, (0[1-9]|[12][0-9]|3[01]) = days 01 to 09 OR 10 to 29 OR 30 to 31, / again, [0-9]{4} = exactly 4-digit year. Like checking calendar validity.
12/25/2024
01/15/2025
03/30/2024
7. Match and extract credit card numbers
Sample transaction.txt file with dummy credit card numbers:
Payment: 4532-1234-5678-9012
Card: 4532 1234 5678 9012
Compact: 4532123456789012
Invalid: 1234-5678-9012
Another: 5555-4444-3333-2222
Short: 1234567890123
We will only extract the credit card numbers:
grep -oE "[0-9]{4}[-\s]?[0-9]{4}[-\s]?[0-9]{4}[-\s]?[0-9]{4}" transactions.txt
Credit cards (usually) follow 4-4-4-4 digit blocks: [0-9]{4} = exactly 4 digits, [-\s]? = optional dash or space, repeated 4 times.
4532-1234-5678-9012
4532 1234 5678 9012
4532123456789012
5555-4444-3333-2222
Now don't show me an American Express card ;)
8. HTML tag removal
Here's a sample HTML code:
<div class="content">
<h1>Welcome to Our Site</h1>
<p>This is a <strong>sample</strong> paragraph.</p>
<a href="https://example.com">Click here</a>
</div>
And we remove all the tags in brackets:
sed 's/<[^>]*>//g' webpage.html
HTML tag elimination uses bracket matching: < = literal opening bracket, [^>]* = any characters EXCEPT closing bracket (zero or more), > = literal closing bracket. Like scissors cutting out everything between angle brackets.
Welcome to Our Site
This is a sample paragraph.
Click here
Bonus tips: Mind these for writing better regex
It is always easy to write a regex that may seem to match your pattern but also end up matching a lot more. I cannot cover all such situations, but here are a few common mistakes you should avoid.
1. Forgetting to escape
# Wrong: will match any character instead of literal dot
grep "192.168.1.1" file.txt
# Correct: escape the dots
grep "192\.168\.1\.1" file.txt
2. Greedy vs non-greedy
# Greedy problem with HTML
echo "<b>bold</b> and <i>italic</i>" | grep -oE "<.*>"
# Returns: <b>bold</b> and <i>italic</i>
# Better approach
echo "<b>bold</b> and <i>italic</i>" | grep -oE "<[^>]*>"
3. Case sensitivity
This is more of a grep feature.
# May miss uppercase variants
grep "email" contacts.txt
# Better: case insensitive
grep -i "email" contacts.txt
4. Anchor your patterns
No need to search entire files if your pattern is at the beginning.
# Slow: searches entire line
grep "pattern" hugefile.txt
# Fast: anchored search
grep "^pattern" hugefile.txt # If pattern is at start
5. Use character classes efficiently
# Slower
grep -E "[0123456789]" file.txt
# Faster
grep -E "[0-9]" file.txt
# or
grep -E "\d" file.txt
6. Testing your regex quickly
The easiest way to test your regex is to feed it the extact match you are looking for. Once it matches that, you can try feeding it patterns that it should not match.
Basically, just echo the pattern to grep.
# Quick test with echo
echo "test string" | grep -E "your_pattern"
You can also use some online regex validator if you want.
Final thoughts
I learned regex from this website several years ago. And yet, I revisit the concepts, specially when I have to understand a complex regex.
To be quite honest, it is never easy to learn or master regex, especially if you don't use it every day. Still, knowing (most of) the metacharacters helps a great deal.
Once you have the basic understanding, you take a look at the regex cheatsheet and you should be able to write some elementary expressions for sure.
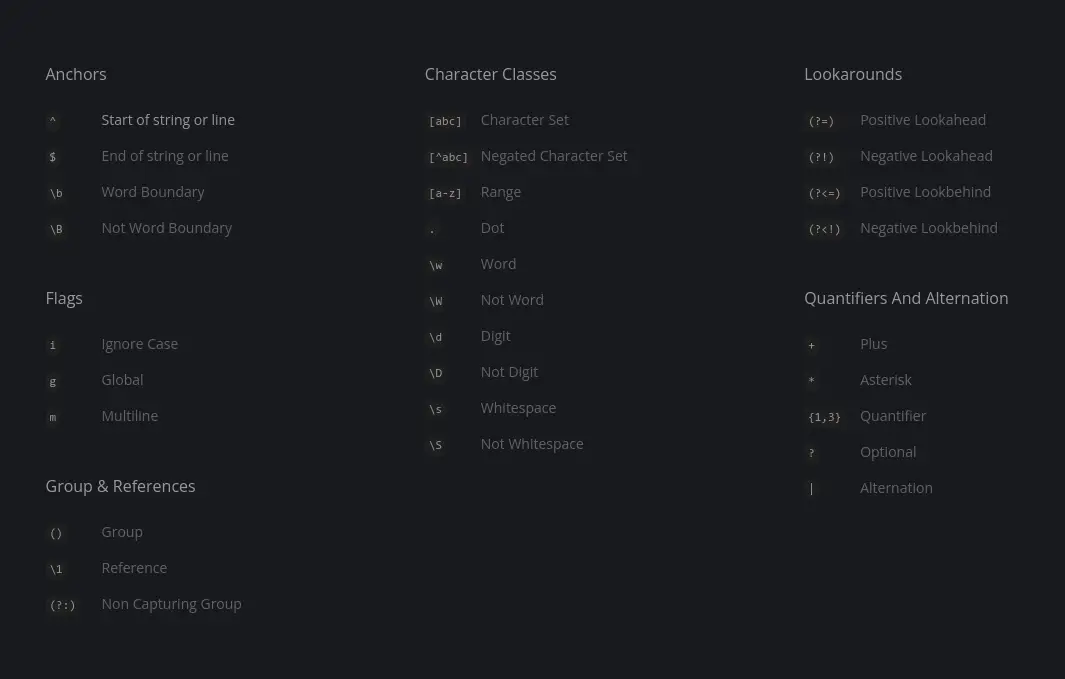
There is a famous joke in the community:
"The number of times I used regex is equal to the number of times I had to learn regex"

Also remember that a readable regex beats clever regex. Future you will thank present you for clear, documented patterns!
